We explored parallelizing bulk operations (e.g., union, intersection, difference, and filter) on ordered sets and maps in OCaml 5 using shared-memory parallelism.
These operations all share a recursive split-join structure with independent subproblems that map onto domainslib’s fork-join scheduler.
Our first implementation parallelized the standard library’s AVL tree directly, achieving good speedup but being limited by the language’s internal memory representation.
We redesigned the data structure to be closer in style to a binary B+tree with sorted-array leaves and a dynamic parallel cutoff, leading to significant speedup over the AVL at comparable parallel scaling, all while remaining a drop-in replacement for the standard Set and Map.
We held our implementation to the same workload assumptions as the stdlib (polymorphic keys, matching asymptotics) for fair comparison, and evaluated it on five benchmarks chosen to cover different common workloads.
In this section we describe sets and maps in general and the standard approaches for implementing them. We then focus on the OCaml runtime and standard library implementation of sets. The goal is to introduce the operations and functionality we are trying to parallelize and how the OCaml runtime makes this task more challenging. Future sections (including our results and analysis) will reference terminology and runtime specifics defined primarily in this section. Given that this was our first time using OCaml for parallelism we made this section quite thorough so some parts can be skimmed or referenced as needed.
Data structures
Ordered Sets and Maps. An ordered set is a collection of totally-ordered keys supporting membership queries, insertion, deletion and iteration in sorted order. An ordered map extends this by associating each key with a value. There are several standard ways to implement them. Hash tables offer expected $O(1)$ time point operations (like lookups, insertions and deletions) but don’t maintain key ordering and don’t efficiently (sub-linearly) support range queries, bulk merging or set operations like union and intersection. Implementations with sorted arrays support binary search and good cache behavior but make inserts and deletes expensive (worst case $O(n)$). Implementations via balanced binary search trees (BSTs) like AVL trees, red-black trees, weight-balanced trees and treaps allow $O(\log n)$ work for inserts and deletes, efficient ordered iteration and support for efficient bulk operations like union, intersection and difference. This makes balanced BSTs a standard choice for workloads using both point operations and bulk or range operations over ordered data.
In imperative languages like C/C++ implementations usually mutate the tree in place to maintain the balance invariants of BSTs. For example an insertion modifies existing node pointers and rebalances the tree by rotating nodes. In functional languages like OCaml rotations are still used but the operations are purely functional (or “persistent”) in that they never modify existing nodes. Instead they create new nodes and share the old tree’s structure via path copying (described in depth later in this section). The old version of the tree stays valid. This persistence makes reasoning about correctness easier since there is no aliasing or mutation and it eliminates data races by construction since no thread ever writes to a location another thread might read. The main cost is allocation since every modification creates $O(\log n)$ new nodes and the garbage collector (something C++ doesn’t have to worry about) must eventually take back the old unreachable ones. This makes the performance question more nuanced for data structure design.
Parallelizing Balanced BSTs. There are two different approaches for adding parallelism to balanced BSTs and sets/maps in general. To avoid confusion with the literature and our work these are defined below.
-
Concurrent access encompasses multiple threads performing independent point operations (like inserts, deletes and lookups) on a single mutable tree at the same time. The challenge is synchronization since two threads might try to rotate the same node or one might read a pointer that another thread is modifying. Using fine-grained locking, lock-free data structures and/or transactional memory can allow for this access to be synchronized. Concurrent BSTs are widely studied in imperative languages with mutable shared state and are useful when many clients need to read and write the same data structure at high throughput.
-
Bulk parallelism involves taking a single operation that touches a large portion of the tree (like a
unionof million-element sets) and parallelizing its internal work.
Bulk parallelism speeds up individual large operations while concurrent access supports many simultaneous small operations. For this project we focus on bulk parallelism. The purely functional setting makes this particularly nice to think about since the data structure is never mutated and there are large forked subproblems that are independent with no synchronization needed.
The OCaml Runtime and the stdlib
OCaml is a statically typed, garbage-collected functional language with both a compiled native-code backend and a bytecode compiler. This project uses the native compiled backend and targets OCaml 5 which was released in 2022 and introduced shared-memory parallelism. Prior to this OCaml’s Thread module created OS threads but the runtime used a single global lock that any thread had to hold in order to execute OCaml code or allocate memory. This kept the runtime and garbage collector simple but it made OCaml unable to support shared-memory parallelism (and is why we chose OCaml 5).
OCaml uses a uniform boxed representation for heap-allocated values. Every heap object is accessed through a pointer to a block which consists of a header word followed by one or more data fields each one word wide. The header word has the block size, a tag identifying its variant/constructor and a few bits used by the garbage collector. OCaml values use a tagged representation. Every value is one word whose low bit distinguishes immediate values (like integers and constructors with no arguments) from pointers to boxed blocks (which are always word-aligned and so end in a $0$ bit). Immediate integers are stored directly in the value slot with the tag bit set so they need no heap allocation and are passed around in registers like normal integers at the cost of losing one bit of range (e.g., 63-bit instead of 64-bit integers). Any value that can’t fit in this tagged representation is allocated on the heap as a block and accessed indirectly through a pointer. Importantly for us this uniform representation simplifies polymorphism and garbage collection but imposes a pointer dereference on nearly every non-integer access and adds a per-block header word of memory overhead that does not exist in languages like C++.
As mentioned earlier in this section OCaml’s standard library data structures are persistent in that operations never modify existing values in place and instead return new values that may share structure with old ones. When a persistent data structure is updated the portions of it that lie along the path from the entry point to the modification point are replaced with new heap blocks while the untouched portions are reused by having the new blocks point directly to the existing ones. This technique is called path copying. So the cost of a single update is proportional to the length of the modified path instead of the total size of the data structure since only the blocks along that path need to be newly allocated. The easiest example for our purposes is a tree node containing a value and pointer(s) to child node(s). To update the value at a deep node the operation walks down from the root to that node and creates a new copy of it with the same fields except for the changed value. That new copy then forces its parent to be reallocated as a new block whose child pointer points at the new copy instead of the original. The same has to happen for that parent’s parent and so on all the way back up to the root.
In general the structural benefit is that the old version of the data structure remains a valid value that can be passed around, stored and read concurrently by multiple workers without synchronization because no code ever mutates it. The memory cost is that every update allocates new heap blocks and these blocks must be reclaimed by the garbage collector. For workloads that perform many updates in sequence path copying produces a steady stream of short-lived heap allocations which need to be collected. We now describe how this garbage collection system works.
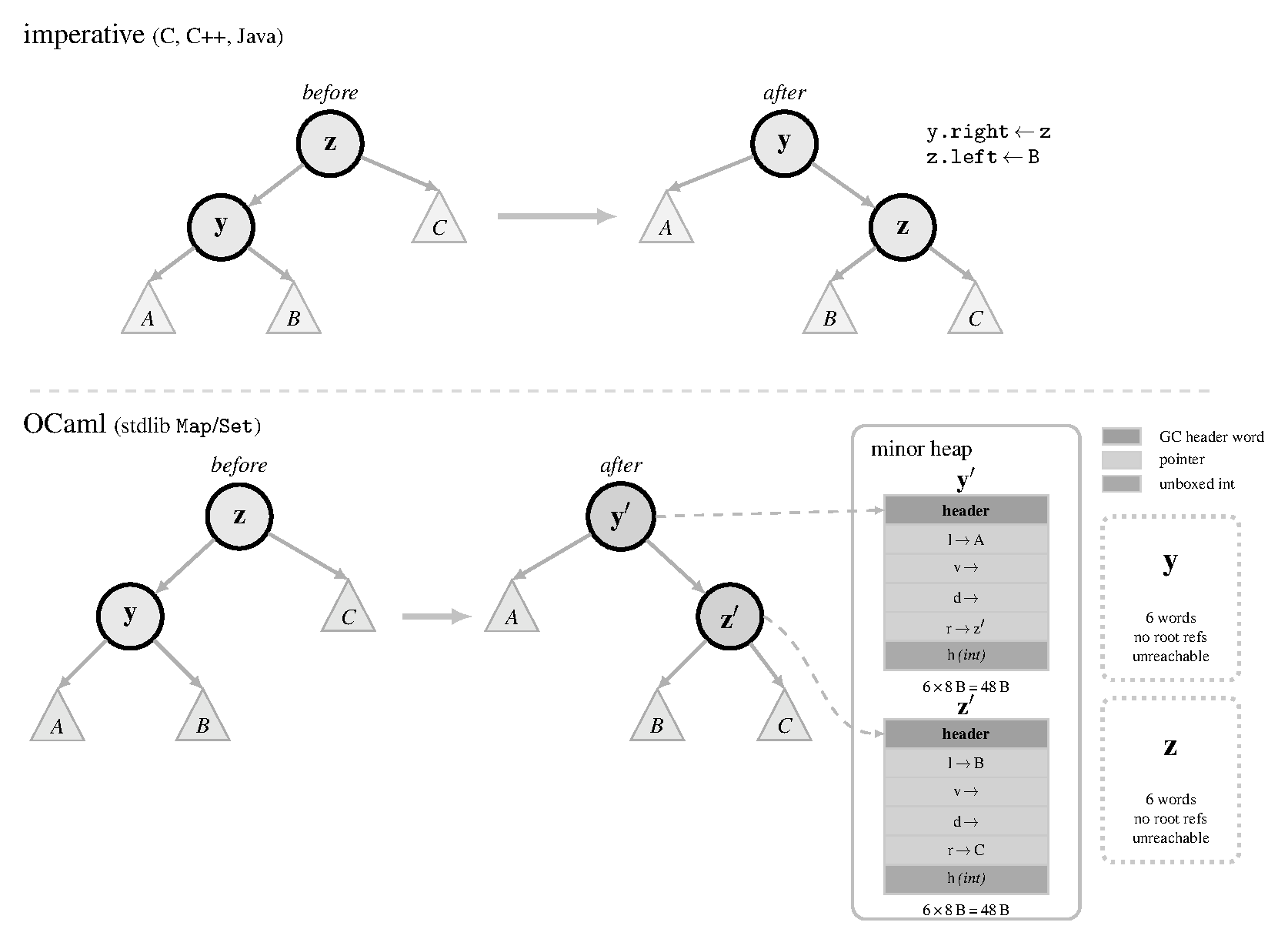
Figure 1. A single tree rotation in imperative languages (top) and in (persistent) OCaml (bottom). In the imperative example, references are reassigned in-place and no new allocations are necessary. In the OCaml example, due to path copying, the reassignment of $y$ and $z$'s internal fields requires them to be reallocated into new blocks on the minor heap while the old versions are now ready to be garbage collected.
Garbage Collection.
OCaml 5’s garbage collector is generational and operates on the hypothesis that most allocated objects die (are no longer referenced) quickly after they are made. The heap is divided into two regions. The first is a small minor heap used for new allocations and the second is a larger major heap used for objects that survive long enough to be promoted. Each domain (OCaml 5’s unit of parallelism) has its own private minor heap typically 2 MB by default but tunable via the OCAMLRUNPARAM environment variable. All domains share a major heap. When a domain exhausts its minor heap it triggers a minor collection (an event that pauses all domains, scans their roots, copies surviving objects from their minor heaps to the shared major heap and then resumes execution). Minor collections are designed to be fast with pause times typically well under a millisecond. The major heap is collected incrementally by a concurrent mark-and-sweep system.
There are a few key points that are important for understanding how this system interacts with parallel workloads that allocate frequently (something we ran into with our implementation). First the minor heap’s small default size means that a workload allocating at a high rate will exhaust its minor heap frequently and trigger many minor collections. Although each individual collection is fast the cumulative cost of hundreds or thousands of minor collections during a single bulk operation can dominate wall time. Because minor collections are stop-the-world every collection forces all active domains to synchronize at a barrier. Second objects that survive a minor collection are promoted to the major heap. For short-lived operations (like a single bulk set operation) ideally all of the allocations die in the minor heap and are collected cheaply and there isn’t much promotion. Promotion is wasted work because the promoted objects will become garbage quickly after and need a more expensive major collection to reclaim. High promotion rates show that the minor heap is being flushed before its contents have time to die (might mean that the minor heap is too small for the operation’s working set). Third the shared major heap introduces contention between domains. The concurrent GC must coordinate its work across all domains and the allocation fast path for the major heap uses atomic operations that can become contention points with more cores.
Memory Representation in the Standard Library Set and Map.
The standard library’s Set and Map modules are implemented as balanced binary search trees (specifically AVL trees). A set is represented as a variant type with two cases. The first case is Empty which is a constructor with no arguments (an immediate value needing no allocation). The second case is Node which is a constructor carrying four fields (left subtree, element, right subtree and height). Each Node is a separate heap block. It has a header word plus four data fields for a total of five words. A Map node has an analogous representation but with an additional word for the value field to which the element/key maps. For a set of $n$ elements the data structure occupies roughly $5n$ words of heap memory (plus whatever the elements themselves need if they are boxed). Because each block is allocated independently by the heap allocator, logically adjacent nodes (e.g., parent and child) may end up at arbitrary addresses in memory. This creates poor spatial locality compared to an (unboxed) array-based representation. So persistence increases the allocation cost of every structural modification since the hardware prefetcher cannot predict where the next node will be from any given location in the tree.
When a single element is inserted into a tree of size $n$ the insertion walks from the root down to the point where the new element belongs and path copying replaces every node along that walk with a freshly allocated Node block whose child pointers are changed to point at either the new subtree or the original untouched sibling subtree. A single insertion therefore allocates $O(\log n)$ new blocks (one for each level of the tree) even though only one element was added. The untouched subtrees on either side of the modification path are shared with the original tree by pointer reuse so no data is copied beyond the path itself but the path blocks themselves are all new allocations that the garbage collector must eventually reclaim. Figure 1 shows an example of a tree rotation operation on OCaml’s Map representation and how it differs from imperative languages where these additional allocations are not necessary.
Bulk operations like union, intersection and difference extend this behavior to the entire output. Each node in the result is a newly allocated block so an operation producing an $n$-element result allocates on the order of $n$ blocks. Across a sequence of updates or bulk operations this produces a continuous stream of short-lived tree node allocations whose lifetime is tied to how long the resulting tree is retained by the caller. This allocation stream is the dominant source of GC activity for any workload using them.
Domains and the Parallelism Model.
Parallelism in OCaml 5 is done through domains which are the abstraction for a unit of parallel execution. A domain corresponds roughly to an OS thread that can execute OCaml code independently of other domains. Domains are spawned via the Domain.spawn primitive. The caller can later Domain.join the handle to wait for the spawned computation to complete. Spawning a domain is expensive compared to spawning a thread in many other languages because the runtime must initialize a new minor heap, GC state and bookkeeping structures for the new domain. This cost makes Domain.spawn unsuitable for fine-grained parallel tasks. Forking a new domain for every recursive call in a divide-and-conquer algorithm would spend more time in domain creation than in useful work. In practice programs spawn a fixed pool of long-lived domains (typically one per core) at startup and dispatch work to them through a higher-level scheduling abstraction, instead of spawning domains dynamically for individual tasks.
OCaml 5 also provides low-level synchronization primitives. Mutex is for mutual exclusion, Condition for condition variables, Semaphore for counting semaphores and Atomic for lock-free atomic references supporting compare-and-swap and related operations. These primitives exist in the standard library but are intended as building blocks for higher-level abstractions instead of as the primary interface for parallel programming.
The recommended way to write parallel OCaml 5 programs is through the domainslib library which provides a higher-level interface built on top of domains. The main abstraction in domainslib is the task pool (a fixed-size collection of worker domains spawned once at program startup). The main domain submits work to the pool as lightweight tasks using an asynchronous interface. Task.async takes a thunk, enqueues it on the pool and returns a promise. Task.await blocks on the promise until the task completes and returns its result. Tasks are distributed among the worker domains by a work-stealing scheduler with each worker domain having a local deque of tasks.
Domainslib additionally provides parallel iteration primitives such as parallel_for which splits a range of indices across workers and is convenient for simple data-parallel patterns. We tried using this to our advantage at points, but it didn’t end up being important in our final design.
Benchmark Setup
We benchmarked against a common set of workloads to isolate the effects of our algorithmic/runtime changes. All inputs are generated deterministically with fixed random seeds and the timed region covers only the bulk set operation itself with measurements averaged over all iterations. Unless otherwise mentioned we used integer keys and values for the benchmarked sets/maps though we made our implementation polymorphic and did not prioritize monomorphic optimizations (e.g., integer sets or bit sets). We defined five input configurations (otherwise referred to as ICs) designed to stress a different part of the implementation’s behavior and be representative of a different common workload. Every configuration was run against union, intersection, difference and filter under different worker counts. The table below summarizes the configurations we used. We ran all experiments on a 6-core AMD Ryzen 5 3600 and on OCaml 5.2.1. Since our implementations used domains-based parallelism we measured speedup over varying domain count and did not exceed the number of available cores on the active machine.
| Config | Description |
|---|---|
| IC-1 | Two trees of $n$ elements each with keys drawn uniformly from $[0, 10n)$ from fixed seeds. This keeps duplicate probability low (${\sim}10\%$), so set sizes are approximately $0.9n$ after set deduplication. Two independently generated trees of equal size with no major special structure. |
| IC-2 | Two trees of $n$ elements each with an exact overlap fraction of $50\%$. Keys are drawn without replacement from $[0, 20n)$ and partitioned so that $0.5n$ keys are shared, $0.5n$ are exclusive to each tree. This exercises the case where a large fraction of the work produces retained output (shared keys pass through to the result for union and intersection), stressing the join and rebalancing paths more heavily than IC-1. |
| IC-3 | Two trees with a 9:1 size ratio ($n_a = 900{,}000$, $n_b = 100{,}000$), with keys uniform from $[0, 10^8)$. This simulates a practical scenario where one incrementally updates a large set. The skew emphasizes the recursive split performance. |
| IC-4 | Two trees of $n$ elements with completely disjoint, sorted key ranges where $a = {1, \ldots, n}$ and $b = {n{+}1, \ldots, 2n}$. Because the keys are inserted in order the resulting AVL trees are almost perfectly balanced and since the ranges do not overlap, intersection and difference terminate at the first comparison at the root. This is a best case for those operations and a stress test of the parallel scheduler since there’s almost nothing to compute. |
| IC-5 | Two trees of $n$ elements where keys are drawn from 20 randomly placed clusters, each with a spread of $20\%$ of the inter-cluster gap. Both trees use the same cluster centers but independent draws. This makes non-uniform key distributions that make unbalanced splits, testing whether the granularity cutoff still produces acceptable load balance with irregular subtrees. |
Collected Metrics
Each benchmark run records wall-clock timing and garbage collection statistics. Wall-clock time was measured with Unix.gettimeofday (we do not use Sys.time which reports CPU time for the calling thread only and would miss work performed by worker domains making parallel runs appear artificially fast). Before the timed loop one untimed warm-up repetition is run to avoid cold-start effects, followed by Gc.full_major() to eliminate garbage from the setup phase. The benchmark then runs $r$ repetitions in a single contiguous loop and measures total elapsed time once before and once after. The per-repetition figure reported is $\text{wall_total} / r$. Because GC is not suppressed between repetitions collections occur naturally and their cost is amortized across all repetitions which approximates a realistic steady-state.
For the GC stats all GC recorded fields are deltas between snapshots taken immediately before and immediately after the timed operation. We record five quantities from Gc.stat():
- Minor collections. The number of minor GC cycles during the operation. Each minor collection is triggered when a domain’s minor heap (default 2MB) fills. All domains synchronize at a stop-the-world barrier and collect their minor heaps in parallel. Because purely functional tree operations allocate a new node for every structural modification, we use the minor collection count as a proxy for allocation rate and frequency of pauses.
- Major collections. The number of major GC cycles. OCaml 5’s major collector is mostly concurrent across domains (with some short stop-the-world pauses). A nonzero value means the timing includes these synchronization barriers plus concurrent GC work that runs on the same domains as the computation and consumes some CPU.
- Minor words. The total words allocated in the minor heap during the operation (one word = 8 bytes on 64-bit systems). This is the most direct measure of total allocation volume. e.g., for
unionof two $n$-element sets the expected allocation is $O(n)$ words for the output tree. - Promoted words. The number of words that survived a minor collection and were promoted to the major heap. High promotion shows that output nodes are living long enough to be considered long-lived by the GC and that increases pressure on future major collections.
- Major words. Words allocated directly in the major heap, bypassing the minor heap. OCaml allocates large objects directly in the major heap. For tree operations (where individual nodes are small) this should be low.
We mostly focus on the minor words allocated, minor collections and major collections.
Approach I (AVL Trees)
As noted in our background, the sequential stdlib implementation of sets and maps uses AVL trees and leaves a balance of performance for sequential point and bulk operations. Our starting point took this approach and structure since we wanted to see whether parallelizing the AVL structure could lead to good speedup gains. Internally each of the bulk operators (union, intersection, difference and filter) is implemented by picking a pivot from one tree (typically its root) and splitting the other tree at that pivot into its left and right halves. We then recursively compute the result on the corresponding pairs of subtrees and join the results back together with the pivot as the separator. Because the two recursive calls operate on disjoint subtrees and share no mutable state they can be run independently which makes this pattern a natural fit for fork-join parallelism. In terms of initial code changes all we needed to do was add the fork/join structure to the existing stdlib implementation that would add these parallel tasks to the domainslib task pool. Initially we set the task size to be as small as possible with tasks being created down to a single node. Ultimately we added a granularity cutoff that (based on the height of the subtrees) would balance the size of the parallel and sequential tasks. Running a sweep over this granularity cutoff we could find the best subtree parallelization cutoff to optimize performance across the different configurations and operators.
In Figure 2 we showed the speedup of our domains-based AVL tree implementation under different cutoff heights. We chose 16 to be our fixed default height cutoff at which point the algorithm would choose sequential evaluation. With jobs being too fine-grained we noticed that the absolute run-time was particularly high since the job-spawning cost was expensive. Each spawned task needed to allocate a Domainslib promise and a closure and a 1M-node tree spawned on the order of millions of such tasks. This mass of short-lived allocations flooded the minor heap and triggered way more minor GC cycles which promoted more objects to the shared major heap and led to more GC pauses. We ran a set of benchmarks in Figures 3 and 4 to illustrate how this impacted the overall performance of the algorithm.
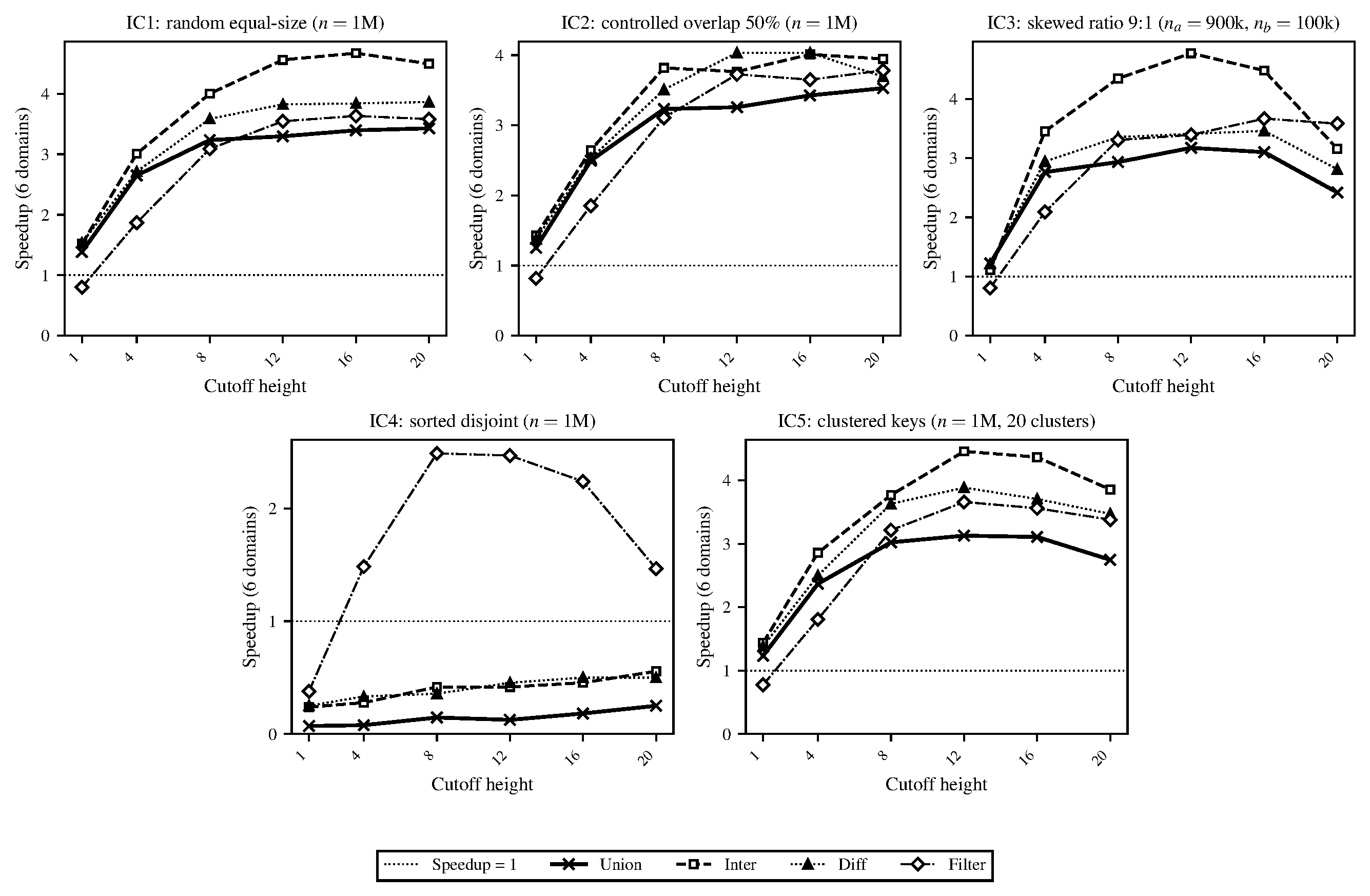
Figure 2. Task granularity sweep for AVL-based parallel implementation of OCaml sets. Speedup relative to single-domain run is averaged over 8 repetitions. Our implementation of maps uses the same implementation but adds an additional value field to each node, showing near-identical performance.
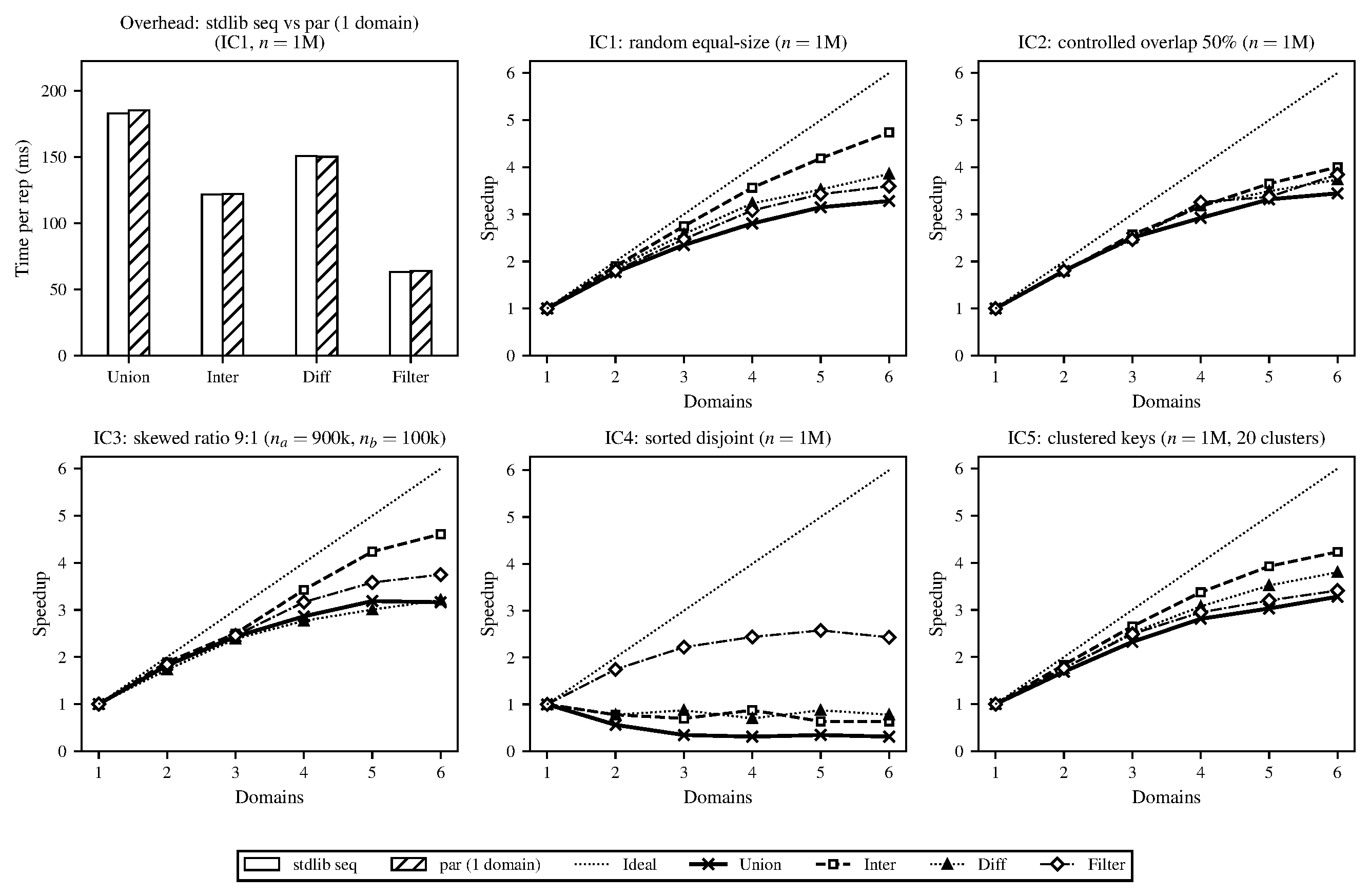
Figure 3. Run-time costs of the parallel, domains-based AVL tree implementation. Overhead over sequential stdlib (top left), along with speedups of each input configuration and bulk operator relative to the single-domain version, at set sizes approximately $10^6$. Task granularity 16 (tree cutoff height) and OCaml's default runtime parameters. Operations repeated 10 times and average run-time taken.
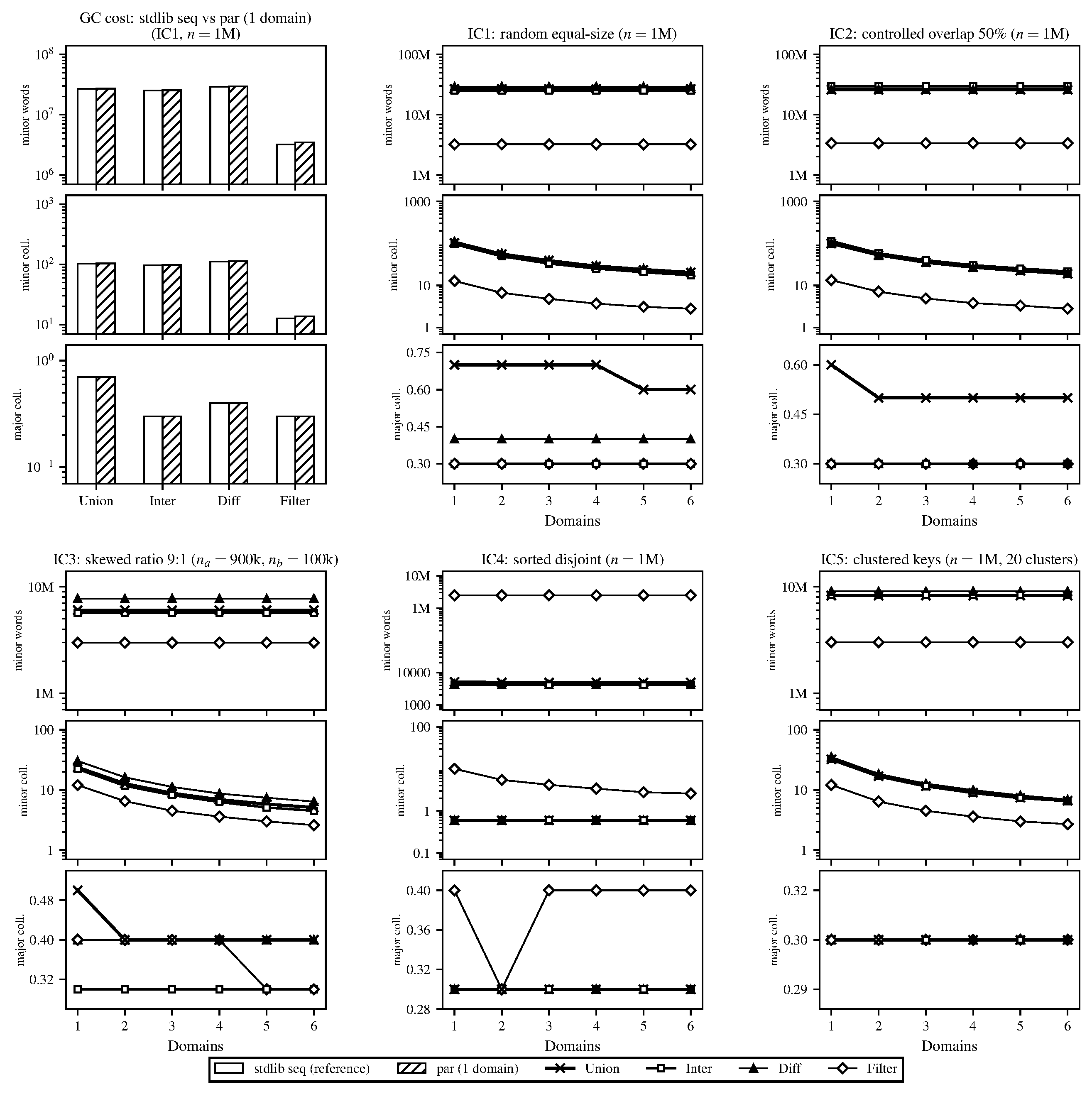
Figure 4. Garbage collector statistics for the same runs as Figure 3. Comparison of overhead over sequential stdlib (top left), along with measured GC statistics for each input configuration and bulk operator relative to the single-domain version.
Looking first at the single-domain overhead comparison in Figure 3 our parallel implementation running with one domain imposed less than 2% overhead relative to the sequential stdlib across all operations under IC1. This showed that allocating the domain pool and registering tasks added negligible cost when no actual parallelism was used. Across the input configurations with meaningful sequential work (IC1, IC2, IC3, IC5) we saw moderate but consistent speedup at 6 domains ranging from roughly 3.2$\times$ to 4.7$\times$. Intersection achieved the highest speedup in nearly every case (up to 4.7$\times$ for IC1 and 4.6$\times$ for IC3) while union consistently achieved the lowest (3.2–3.4$\times$). Diff and filter were in between.
In IC4 (sorted, fully disjoint) the two input sets were completely non-overlapping so the split operation short-circuited after traversing only the leftmost or rightmost path of the other set. This made union, intersection and difference all complete in roughly $O(\log^2 n)$ time (around 9$\mu$s for $n = 1$M). At 6 domains the same operations took 29$\mu$s, 11$\mu$s and 9$\mu$s respectively. When the sequential cost of an operation was so quick the overhead of scheduling even a small number of Domainslib tasks exceeded the useful computation. Filter remained a non-trivial operation since it had to visit every element (regardless of the set structure).
The GC statistics in Figure 4 helped explain some of what we saw in the speedup results, with operations that allocated the most output being those with the lowest speedup. Path-copying produced a new tree on every call and the size of that result varied significantly by operation (e.g., intersection can only be as large as the smaller input while union may be as large as both combined). The GC figure shows this directly in the major-heap promotion rates and the speedup figure shows it in performance. Newly allocated nodes filled the minor heap, survived a minor collection and were promoted to the shared major heap where they eventually triggered a major GC that briefly stopped all domains. The more output a parallel run produced the more frequently this happened and the more time all domains spent waiting. Since the single-domain runs showed the same allocation behavior it appeared this was not an effect of the parallel implementation but parallelism made the cost worse because all domains share a single major heap and all must halt together when a major collection occurs.
Structural Ceilings on Speedup. Even with GC pressure fully under control, the AVL approach plateaued well below the 6$\times$ ideal. The fundamental issue was the memory access pattern. OCaml allocates objects sequentially in the minor heap and promotes them to the major heap in order. After one or more GC cycles the live objects in a large tree are scattered across the major heap with no spatial locality. Every node visit is a potential cache miss since the left and right children of any node may be located anywhere in the heap and the split/join algorithm visits $O(n)$ nodes in total across the $O(\log n)$-deep recursion. With 6 domains all traversing the same 80+MB tree concurrently they rapidly exhausted the machine’s 32MB shared L3 cache and had to fetch from main memory. The pointer-chasing here comes from the representation itself. This ceiling motivated our shift to the new representation described in the next section, which compresses many elements into contiguous sorted-array leaves and reduces the number of heap objects that must be traversed which makes the leaf-level work far more cache-friendly.
Attempts to Optimize the AVL Approach.
Before changing the underlying representation, we mention some ways we explored to reduce the inefficiencies visible in the baseline AVL tree approach. For the most part, this didn’t help too much with performance.
Size-Based Granularity Cutoff. In an AVL tree the node count at a given height varies by up to 25$\times$ (e.g., a subtree of height 16 may contain between 2,583 and 65,535 nodes). This means the sequential leaf tasks can differ dramatically in runtime which leaves some cores idle while others finish and leads to load imbalance. To test whether this was limiting speedup we modified the Node record to carry an extra node-count field (costing one additional word per node) and switched the granularity threshold from tree height to actual node count so that every sequential leaf task would process roughly the same number of elements. On IC1 at $n = 10^6$ with 6 domains the effect was negligible for every operation except inter. The other three operations (union, diff and filter) all came in 1–2% slower than the height-based baseline while inter improved by roughly 7% (from 0.342s/rep to 0.317s/rep). At a single domain the size-based cutoff made no measurable difference on any operation, so the change did not regress the underlying sequential work. For uniformly random input data the height-based cutoff already spawned enough tasks (tens of thousands at a height-16 threshold on a 10M-element tree) so there was low variance and balancing the leaves more tightly did not change the wall time. Since the inter improvement by itself did not justify paying one additional word per node on every operation we rolled the change back.
Disjoint-Input Short-Circuit. We also tried adding an explicit max-of-$s_1$ vs. min-of-$s_2$ check at the top of each bulk operation to skip the recursion entirely when the two inputs are disjoint (returning concat s1 s2 for union, Empty for intersection, and s1 for difference). The intuition was that this would make IC4 essentially free. In practice it made no measurable difference. IC4 was already fast (around 9$\mu$s at $n = 10^6$) because the split operation short-circuits. For every other configuration the disjointness check nearly always failed and added two $O(\log n)$ boundary lookups per call without saving any work.
We tried a few other smaller ideas but ultimately we found that none of these changes helped with our profiling. Running perf on the sequential single-domain IC1 union at $n = 10^6$ showed an L1-cache miss rate of 4.8% and an overall cache miss rate of 25.4% with the operation completing at only 1.17 instructions per cycle (roughly a third of what we expected). At 6 domains the miss rate stayed identical but IPC dropped to 0.82, so the additional slowdown under parallelism likely came from cores contending on the same memory and not from scheduling or synchronization. Our hypothesis was that much of the slow down came from every single element of the set sitting in its own Node record, so a bulk operation on $n$ elements incurred on the order of $n$ such misses no matter how the work was scheduled.
For our final approach we used our failed optimizations, profiling and benchmarks for our AVL implementation to redesign the data structure to better suit the OCaml runtime model. Of the approaches we tried we found that variations closer to a B+tree representation meshed best with the OCaml GC and memory access patterns. Based on the bottleneck we found above we decided to try a different representation of nodes where data was arranged proximally to reduce the amount of heap objects allocated and (for unboxed key types) reduce the amount of indirection necessary to process the large bulk operations.
Approach II (B+Trees)
The AVL profiling in the previous section showed that one major bottleneck was the number of heap-resident nodes the operation had to touch. With one element per node pointer chasing and path-copying, cost scaled with $n$ and dominated. Our intuition was to keep fewer heap objects by clustering many elements into the same block.
The approach we settled on ended up being a modified binary B+tree. A B+tree is a search tree where all the actual data lives in the leaves and the internal nodes carry only separator values used to route queries. The “binary” part means that internal nodes have exactly two children which is what the AVL already used. In the AVL, a leaf was a single Node record storing one element. In the B+tree each leaf was a sorted array of up to $b_{\max}$ elements. A tree of $n$ elements then contained only about $n / b_{\max}$ leaves and a similar number of internal nodes which reduced the total heap-object count by a factor of roughly $2 b_{\max}$.
Point operations keep the same asymptotic cost but with better constants. A lookup walks the tree down to the correct leaf in $O(\log (n / b_{\max}))$ jumps then finishes with a binary search inside that leaf’s array which takes $O(\log b_{\max})$ steps. The overall cost is still $O(\log n)$ but the internal walk is shorter and the final array search runs inside a single contiguous heap block.
Bulk operations use the same recursive split-join pattern as the AVL but in the base case (when the recursion reaches a pair of leaves) it doesn’t recurse into individual elements. Instead it runs a linear merge over the two sorted arrays and writes the output into a newly allocated array. If the result exceeds $b_{\max}$ it’s rebuilt into a smaller balanced subtree. The overall split-join shape didn’t change but most of the work at the element level happened inside contiguous arrays and the number of heap objects allocated during the operation dropped proportional to $b_{\max}$.
The cache benefits described above are clearest for unboxed key types (like integers on which we run most of our benchmarks) where each element sits inline in the leaf array and a comparison is a single word load. For boxed key types such as tuples, records or strings the leaf array instead holds pointers to separately allocated key blocks so each comparison includes one pointer dereference to whatever heap location the key happens to live at. That extra dereference is an additive cost that both the AVL and the B+tree pay on the same number of comparisons. So the B+tree’s relative advantage shrank but (from our experiments) didn’t fully go away. We ran quick experiments on tuple keys and the absolute speedup of the B+tree over the AVL dropped from roughly $4\times$ on integer keys to around $1.7\times$ while the reduction in minor and major allocation stayed at about $3\times$ in both cases. The structural improvement (i.e., fewer internal nodes, a shorter tree walk and one leaf block per $b_{\max}$ elements) depend on the tree’s shape and not the block representation so they apply to any key type.
Choosing Parameters ($b_{\max}$ and Parallel Height Cutoff).
The leaf size was a direct tradeoff which we tried to optimize. Larger $b_{\max}$ means fewer heap objects and longer contiguous memory chunks at the leaves while also making add and remove more expensive. The sorted-array invariant forces a full copy of the leaf tail on every update and every split or leaf-level merge allocates a temporary array of (up to) $2 b_{\max}$ elements. To find a good value we ran an initial sweep over $b_{\max}$ and the parallel cutoff height on IC1 at $n = 10^6$ with 6 domains. Sequential time was minimized around $b_{\max} = 128$. Small leaves wasted time on many internal nodes and large leaves wasted time shuffling leaves’ arrays on every update. We fixed $b_{\max} = 128$ as the default and moved on to finding a good parallel cutoff height.
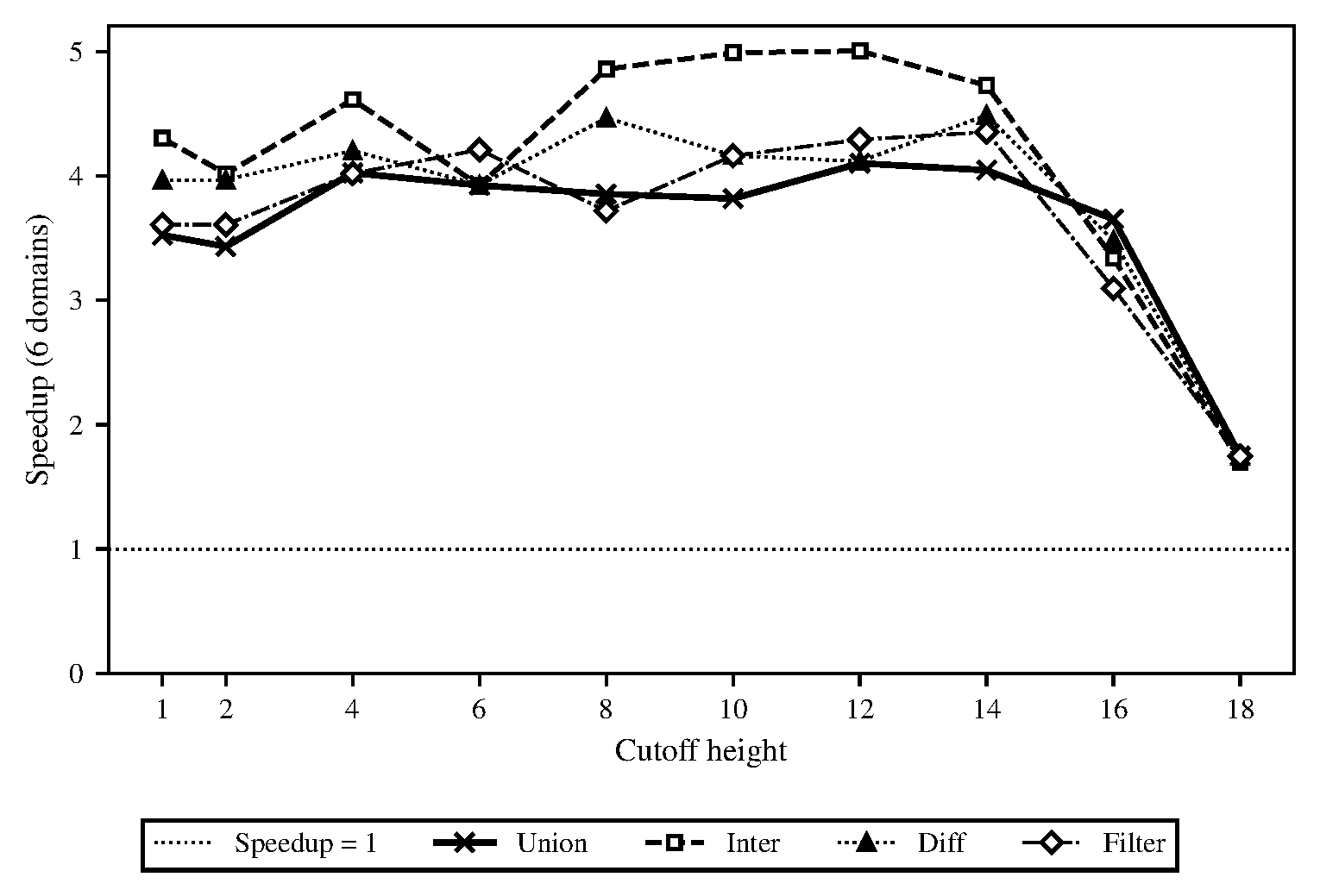
Figure 5. Cutoff-height sweep for the B+tree implementation at $b_{\max} = 128$, $n = 5 \times 10^6$, 6 domains, 3 repetitions per configuration. The cutoff height was chosen to be $\max(4, h - 4)$, where $h$ is the smaller of the two input tree heights for binary operations, or simply the tree height for filter.
We then swept the cutoff height from 1 to 18 at $n = 5 \times 10^6$ on 6 domains (see Figure 5). The speedup was mostly flat across the range until the larger cutoffs (which were close to the height of the tree and no splits ran in parallel anymore). We also noticed that the plateau changed depending on $n$ which made sense because a taller tree can have a higher cutoff while still creating enough forks. Since this depended on the height of the tree we computed the cutoff dynamically at the start of each parallel call as $\max(4, h - 4)$ (fast to compute since we had the height stored in the node directly). This created about $2^4 = 16$ top-level forks which was enough to keep all six domains with their work stealing.
For binary operations where the two input trees can have different heights we set $h$ in this formula to be the smaller of the two heights. This was an important change because we found that unbalanced workloads slowed down when using the wrong tree’s height cutoff. The recursion stops forking as soon as either subtree drops below the cutoff so the shorter tree limits the depth of where parallel work is created. Using the larger height for asymmetric inputs (like IC3) set the cutoff too coarse for the smaller tree and left only a few forks before the recursion became sequential. We confirmed this experimentally in our runs where IC3 improved after setting the smaller tree height (the other configurations weren’t negatively impacted).
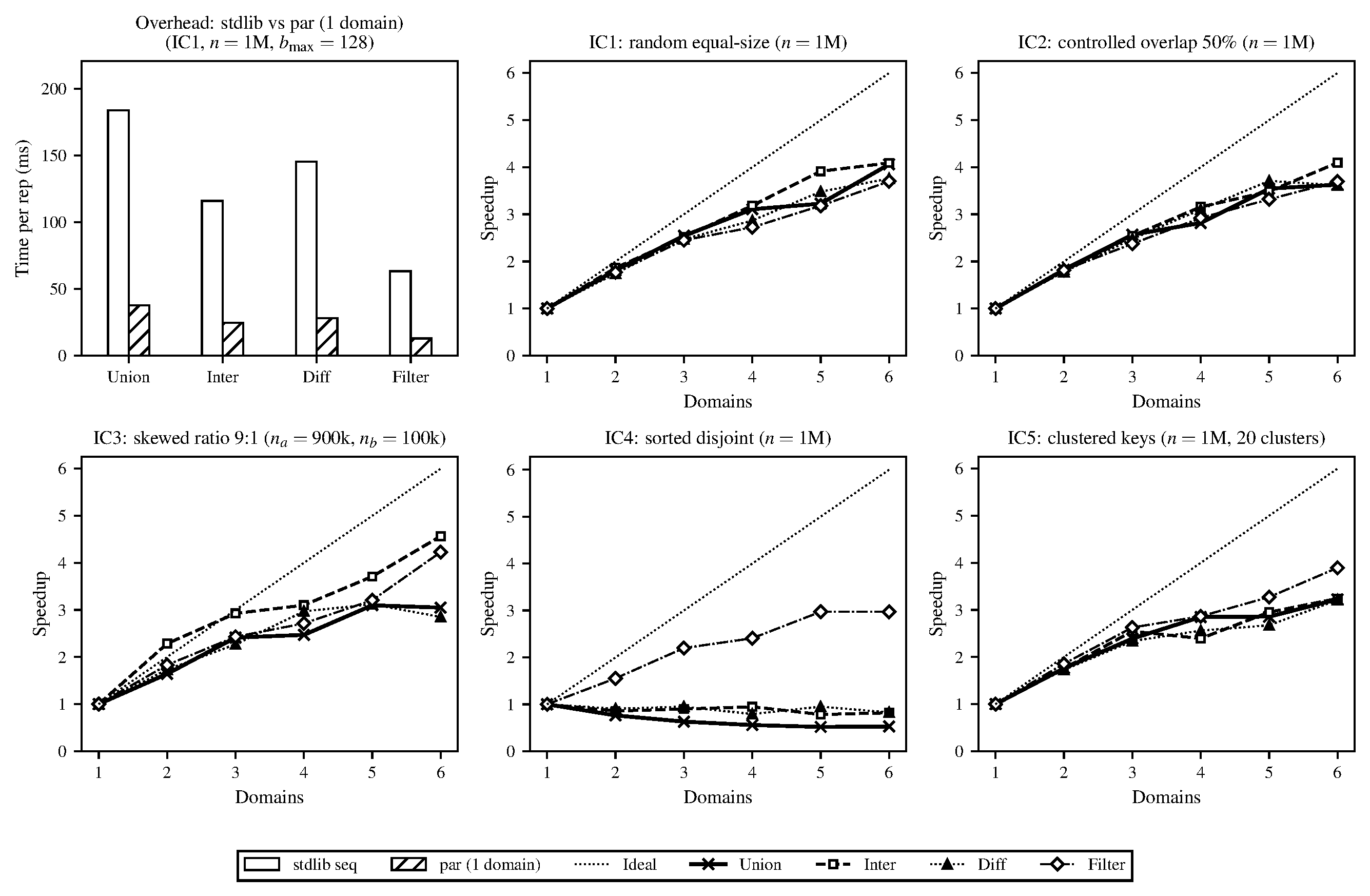
Figure 6. Run-time costs of the parallel B+tree implementation. Overhead over sequential stdlib (top left), along with speedups of each input configuration and bulk operator relative to the single-domain version, at set sizes approximately $10^6$. $b_{\max} = 128$, dynamic cutoff rule $\max(4, h_{\min} - 4)$, default OCaml runtime parameters. Operations repeated 10 times per configuration and averaged.
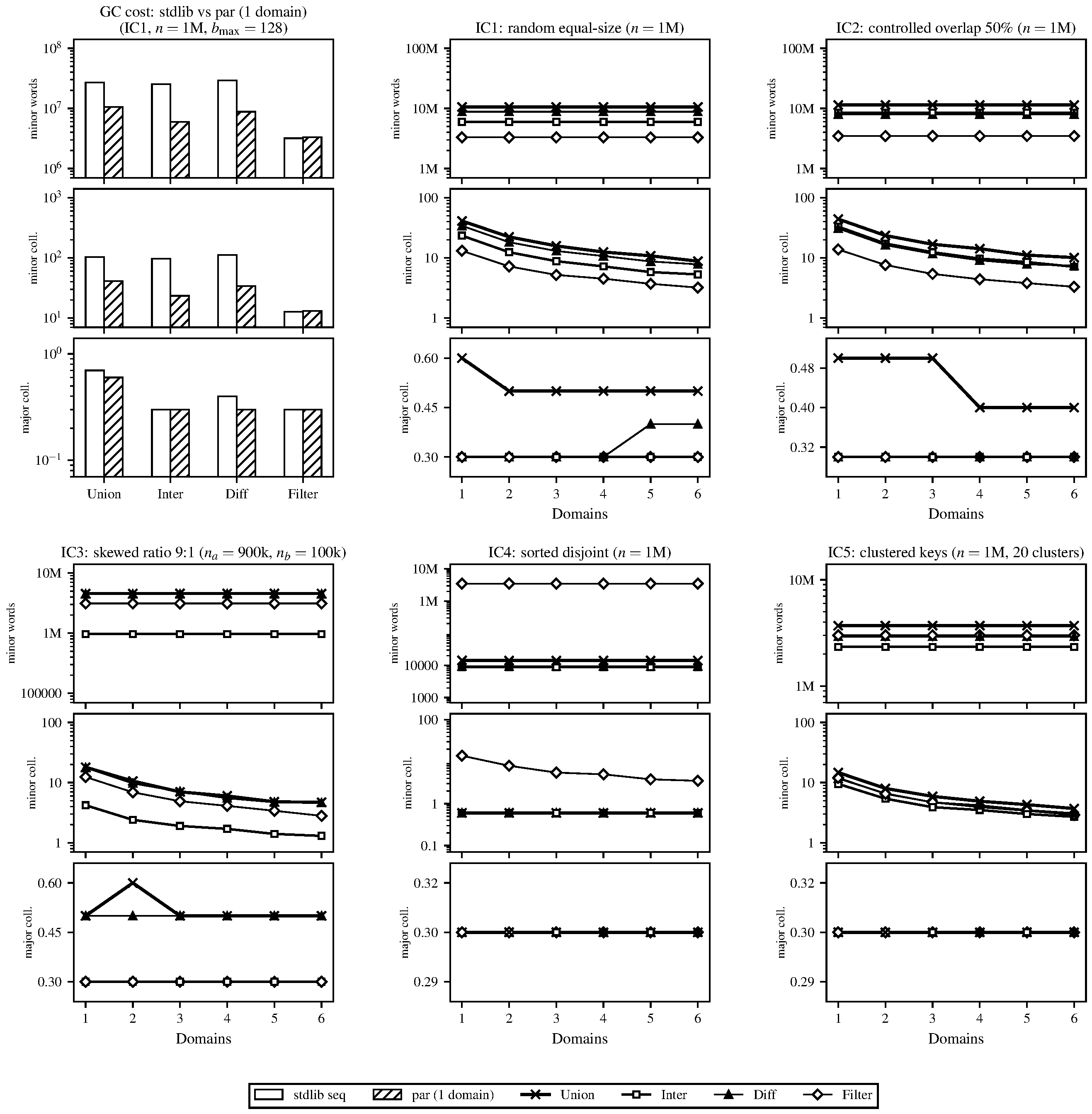
Figure 7. Garbage collector statistics for the same runs as Figure 6. Overhead over sequential stdlib (top left), along with measured GC statistics for each input configuration and bulk operator relative to the single-domain version.
Figures 6 and 7 show the speedup and GC results at $n = 10^6$ across the same benchmarks as used for the AVL. Every operation finished roughly five times faster than the AVL, both at one domain and at six, across all four operations. The speedup ratios were in the same range as what the AVL reached (around $3$ to $4.5\times$), scaling pretty much the same way but doing each unit of work much faster. As before, intersection and filter still scaled best because their outputs were small and imposed less GC pressure and union scaled worst because it produced the largest output. IC4 (sorted disjoint inputs) still showed no parallel benefit on the binary operations because the sequential implementation already completed in a few microseconds which was faster than the cost of spawning a task.
| Metric | AVL | B+tree |
|---|---|---|
| Wall time and GC | ||
| Wall time per rep | 610.9 ms | 114.8 ms |
| Speedup over AVL (wall) | 1.00× | 5.32× |
| Minor words allocated per rep | 268.3 M | 115.7 M |
| Major-heap words per rep | 81.5 M | 20.4 M |
| Minor GCs per rep | 189.7 | 83.8 |
| Major GCs per rep | 0.60 | 0.38 |
| Hardware counters | ||
| IPC (instructions per cycle) | 0.71 | 1.29 |
| Backend-stall cycles | 48.3% | 33.0% |
| Frontend-stall cycles | 15.2% | 11.3% |
| Cache miss rate | 26.1% | 31.5% |
| Cache misses per rep | 103.8 M | 24.0 M |
| Branch miss rate | 2.44% | 1.79% |
| Cycle breakdown | ||
| Useful compute | 40.1% | 34.8% |